
In this laboratory you will study some aspects of the random nature of radioactive decay. You will verify that if the count rate is low, the probability of recording a particular number of counts is given by the Poisson distribution, and that if the count rate is high, the probability of recording a particular number of counts is given by the Gaussian distribution.
You will observe that when counting random events, the actual number of counts recorded (N) is often very different from the average number of counts recorded (N). Approximately 1/3 of the time the actual number of counts N will differ from the average number of counts N by more than the standard deviation σ = N1/2. The relative standard deviation σ/N = N-1/2 decreases as N increases. When counting a large number of random events the percentage difference between the actual number of counts N and the average number of counts N is likely to be much smaller and the measurement will have a much higher statistical significance than when counting a small number of random events.
Background information:
There are many types of events that that occur at a well defined average rate, but for which we cannot predict the outcome of any particular measurement. For example, a light bulb has an average lifetime. But we cannot predict how long a particular light bulb will last. This is a characteristic of a random process. A random variable is a function that associates a unique numerical value with every outcome of an experiment. The value of the random variable will vary from trial to trial as the experiment is repeated. For the light bulb the experiment is measuring its lifetime, and the random variable is the number of days it produces light before it burns out.
The average number of rain days in May in Nashville is 11. We cannot predict how many rain days Nashville will have next year in May and on which days it will rain. If we record the number of rain days next May, the new number will most likely differ from that of the preceding May. The number we will record cannot be predicted using the knowledge of a preceding observation nor can it be used to predict the following observation.
Radioactive decay is a random process. We cannot predict exactly when a certain unstable nucleus will decay, we can only predict the probability that the nucleus will decay in a certain time interval. Similarly, we cannot predict exactly how many decays will take place in a particular radioactive sample in a particular time interval, but only the average number of decays. If we actually count the number of decays in several time intervals, we get a different number of counts each time, but they have a more or less definite mean.
Assume we count the number of times N a given random event occurs in a certain time interval. Statistical theory predicts that if we repeat our experiment m times, we will find the numbers N1, N2, N3, ..., Nm. We can calculate the average number of counts N = [Σ1m Ni]/m. The actual number of counts will be distributed around this average value. Numbers close to the average will be recorded frequently, numbers very different from the average will be recorded infrequently. If we want to know how the actual number of events counted in a time interval ∆t is distributed around the average number of events counted in ∆t, we can make histogram of the number of times a certain number N appears.
For a large number of rare events we find that the probability of recording a particular number N is given by the Poisson distribution:
P(N) = NN exp(-N)/N!

The Poisson distribution describes a wide range of phenomena in the sciences. It describes the probabilities of random occurrences and it can be applied to "intervals" on the space or time axes.
For a large number of frequent events we find that the probability of recording a particular number N is given by the Gaussian distribution:
P(N) = [1/(2πN)]1/2 exp[-(N-N)2/(2N)]
For a large N the Poisson distribution approaches the Gaussian distribution.
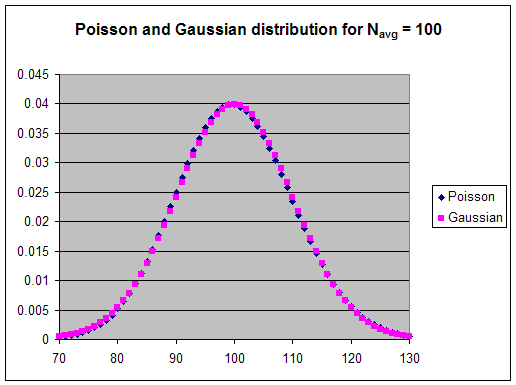
Statistical theory predicts that the standard deviation of the Gaussian distribution is given by σ = N1/2. The standard deviation σ is a measure of the width of the distribution. Approximately 1/3 of the counts will lie outside the interval N - σ to N + σ.
The standard deviation is calculated using
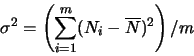 .
.
Equipment needed:

The Geiger-Mueller (GM) tube is a simple device for detecting radiation.
It is a gas-filled metal cylinder (the cathode) with a wire (the anode) running
down its axis. The wire is insulated from the cylinder. A
high-voltage establishes a potential difference between the anode and the
cathode. The anode potential is positive with respect to the cathode
potential. The resulting electric field inside the cylinder has its
largest magnitude near the anode.
When a alpha or beta particle or gamma-ray passes through the cylinder, it ionizes some of the gas, removing the outermost electrons from some of the gas atoms. These electrons are accelerated towards the anode by the electric field, and quickly gain enough kinetic energy to ionize more gas atoms. An avalanche of electrons reaches the anode and produces a pulse large enough to be detected.
The Geiger tube is mounted vertically in a stand. The Pasco Interface receives the pulses from the GM tube and transfers data to the PC.
Part 1:
Part 2:
Data Analysis:
Part 1:
P(N) = NN exp(-N)/N!
Since we made 2500 measurements, 2500*NN exp(-N)/N!
is the number of times we expect to record N counts. Into column C
enter the formula for the expected distribution.
Type = 2500*N^A3*exp(-N)/Fact(A3)
into cell C3, where N is the mean Data Studio calculated for you.
Copy the formula into the remaining cells of column C.
Part 2:
P(N) = [1/(2πN)]1/2 exp[-(N-N)2/(2N)]
Since we made 2500 measurements, 2500*[1/(2πN)]1/2
exp[-(N-N)2/(2N)]
is the number of times we expect to record N counts. Into column C
enter the formula for the expected distribution.
Type = 2500*(2*pi()*N)^(-1/2)*exp(-((E3-N)^2/(2*N)))
into cell G3, where N is the mean Data Studio calculated for you.
Copy the formula into the remaining cells of column C.
Open Microsoft Word and prepare a report.
Summarize the experiment.
Insert your Excel graphs and discuss your results. In the discussion you should answer the following questions.
For part 1, what was the average number of counts in a 0.2 s time interval?
What is the formula for the expected distribution?
Does a plot of f versus N resemble the expected distribution?
For your measured distribution what is the ratio of the full width at half maximum (FWHM) to the average? Why might you be interested in this value?
For part 2, what was the average number of counts in a 0.2 s time interval?
What is the formula for the expected distribution?
Does a plot of f versus N resemble the expected distribution?
For your measured distribution what is the ratio of the full width at half maximum (FWHM) to the average? Why might you be interested in this value?
Add any comments or questions you may have.